今回は、こんなお困りの声に対応するガジェットです。
「毎日、毎日発注書の山。月末の請求までにこれを取引先ごとに全て処理してまとめて、なんでシステム化していないの。。まとめるだけで一苦労。さらに請求書に落とし込まないといけないし。自動的に発注書をまとめて、請求書作ってくれないかな」

毎日送られてくる大量の書類を自動で処理します
毎日送られてくる注文表。月末にその注文表から商品、個数、金額などをまとめて請求書を作成する。日々やってくる注文表(Excel)をフォルダから取り出して、都度、vlookなどを駆使してまとめ、さらに請求書(Excel)に転記する。日々の注文表もどんどん溜まっていき、とても面倒です。
今回は、毎日送られてくる注文表をあるフォルダに投げ込んでおけば、毎日定期的に、自動でその日の分を集計し当月分として積み上げる。また月末に予定を設定しておけば自動で積み上げたデータから請求書を整形して出力してくれるというガジェットです。自分でやることは毎日フォルダに注文表を入れるだけです。
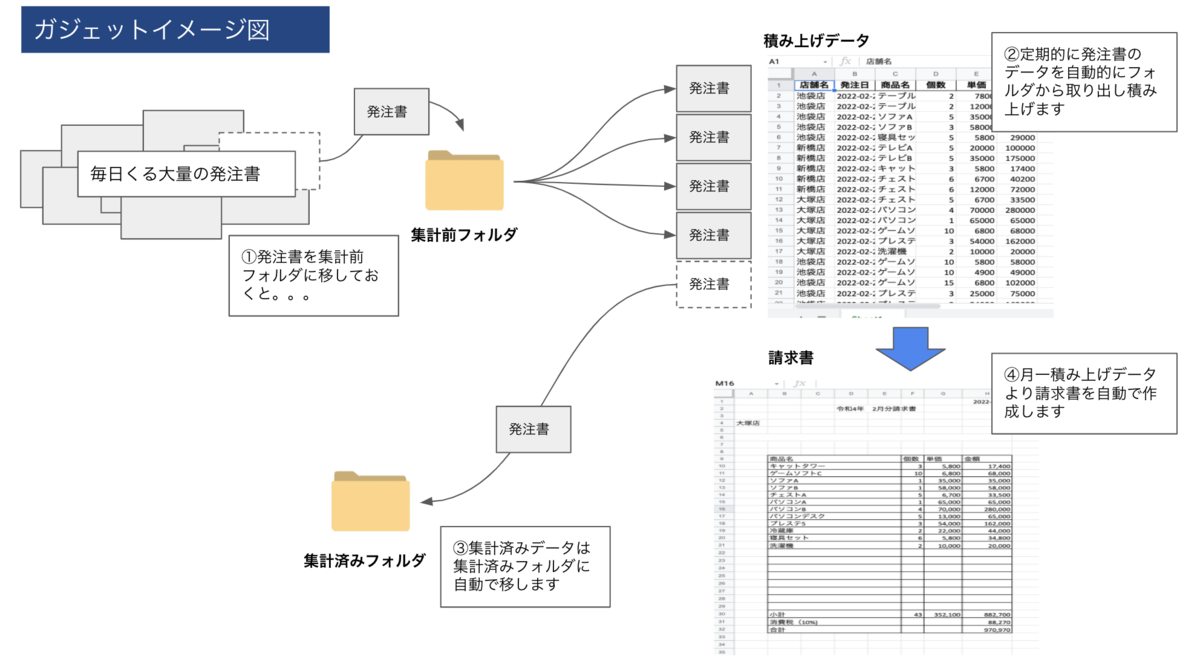
このガジェットでできることはこちら
- 積み上げ前フォルダに注文表を格納すれば、設定した時間にその日の注文表のデータを積み上げデータに追加し集計。
- 処理した注文表は処理済みフォルダに自動で移動するのでデータの重複を防ぎます。
- 商品価格はマスターデータからその都度引っ張りますので、マスターデータを修正するだけで、日々価格が変わる場合も対応可能。
- 積み上げファイルから店舗、商品、個数、金額をまとめ店舗ごとの請求書を自動で作成。 単価が途中で変更になったものは別の行で単価ごとに表示。
注意点はこちら
- 価格変動が激しいときはマスターデータの変更ログをとる設定を追加した方が良いですが、その機能はまだ未対応です。
評価(自己)
役立ち度 ★★★★(良し)
効率化 ★★★★(良し)
ミス防止 ★★★★(良し)
楽しさ ★★★(平均)
操作性 ★★★★(良し)
実行環境
使用環境 Excel、mac(automater、カレンダー)
使用言語 python
使用ライブラリ datetime、openpyxl、pandas、glob、shutil
今回のコード
※実行ファイルは毎日実行するstack.py、月に一回実行するmakebill.pyの2つです。
from glob import glob
import pandas as pd
import shutil
def main():
files = glob('積上前フォルダ/*.xlsx')
df_order = pd.DataFrame()
for file in files:
_df = pd.read_excel(file)
df = pd.DataFrame()
df = pd.concat([df, _df.iloc[9:,[1,7]]])
df.columns = ['商品名', '個数']
df['個数'] = df['個数'].astype(int)
df['発注日'] = _df.iloc[3, 2]
df['店舗名'] = _df.iloc[3, 8]
df = df.iloc[:, [3, 2, 0, 1]]
df_order = pd.concat([df_order, df])
shutil.move(file, '積上後フォルダ')
df_order = df_order.reset_index(drop=True)
df_master = pd.read_excel('product_master.xlsx')
df_master['単価'] = df_master['単価'].astype(int)
df_master = df_master.rename(columns={'商品': '商品名'})
df_order = pd.merge(df_order, df_master[['商品名', '単価']], how='left')
df_order['合計金額'] = df_order['個数'] * df_order['単価']
ex_stacked = pd.read_excel('stacked_order.xlsx')
ex_stacked = pd.concat([ex_stacked, df_order])
ex_stacked.to_excel('stacked_order.xlsx', index=False)
df_stacked = pd.read_excel('stacked_order.xlsx')
pivot = pd.pivot_table(df_stacked, index='商品名',columns='店舗名', values='合計金額', aggfunc='sum').fillna(0).astype(int)
li = []
for i in pivot.columns:
li.append(pivot[f'{i}'].sum())
total_amount = pd.DataFrame({'合計金額': li}, index=['大塚店', '新橋店', '池袋店']).T
pivot = pd.concat([pivot, total_amount])
pivot.to_excel('pivot_data.xlsx')
if __name__ == '__main__':
main()
import datetime as dt
import openpyxl
import pandas as pd
from glob import glob
def main():
today = dt.date.today()
tenpos = df_stacked['店舗名'].unique()
for tenpo in tenpos:
per_tenpo = df_stacked[df_stacked['店舗名']=='新橋店'].groupby(['商品名', '単価']).sum()
name_list = [i[0] for i in per_tenpo.index]
price_list = [i[1] for i in per_tenpo.index]
shukeis = per_tenpo.sum()
bill = pd.read_excel('bills/bill_feb.xlsx')
bill.iloc[9:9+len(per_tenpo.index),1] = name_list
bill.iloc[9:9+len(per_tenpo.index),5] = per_tenpo['個数']
bill.iloc[9:9+len(per_tenpo.index),6] = price_list
bill.iloc[9:9+len(per_tenpo.index),7] = per_tenpo['合計金額']
bill.iloc[29,5] = shukeis[0]
bill.iloc[29,7] = shukeis[1]
bill.iloc[30,7] = int(shukeis[1]*0.1)
bill.iloc[31,7] = shukeis[1] + int(shukeis[1]*0.1)
bill.iloc[3, 0] = tenpo
bill.iloc[0, 7] = today
bill.to_excel(f'bills/{tenpo}_feb.xlsx', index=False, header=False)
bills = glob('bills/*店_feb.xlsx')
for bill in bills:
wb = openpyxl.load_workbook(bill)
sh = wb.active
for i in range(21):
sh.merge_cells(f'B{i+9}:E{i+9}')
for i in range(3):
sh.merge_cells(f'B{i+30}:E{i+30}')
sh.merge_cells('A6:i6')
sh.column_dimensions['F'].width = 6
sh.column_dimensions['G'].width = 10
sh.column_dimensions['H'].width = 13
for i in range(21):
sh[f'G{i+10}'].number_format = '#,##0'
for i in range(24):
sh[f'H{i+10}'].number_format = '#,##0'
from openpyxl.styles.borders import Border, Side
side = Side(style='thin', color='000000')
border = Border(top=side, bottom=side, left=side, right=side)
for row in sh['B9:H32']:
for cell in row:
cell.border = border
wb.save(bill)
if __name__ == '__main__':
main()
以上になります